Gravity— An MMAP Allocator
A personal project, which if I now look back, is a competitive programming problem!
Repo: https://github.com/nnanto/gravity
Gravity is like a memory allocator i.e, given some data, we’ll organize the data (or free them) in our memory. Also, as we walk through the project, we’ll derive questions that are similar to those in competitive programming
Yes, we are the person with the cap but we would do much less in this project. But is there a scenario where this allocator will be useful? There might be. In languages with garbage-collector, storing a lot of data in memory causes long pauses during the garbage collection cycle. There are many optimizations that are usually done to prevent this. We are going to tackle it by allocating objects to an MMAP-ed region.
MMAP maps a part of a file or a region into the memory of the process. This memory is outside of the garbage collector’s scope and hence garbage collection cycle is not dependant on this.
A good use case I’ve seen this being used is for building an in-memory cache (as we’d know the lifetime of objects)
Interface
Let us assume the MMAP system call will return us an array of bytes (so our memory is []byte). We’ll write an allocator to allocate data on this array.
To put it in other words, given a larger byte array (memory), we’ll be writing smaller byte arrays (data) on it. Our allocator will expose three methods.
- Write([]byte) -> pos
We get []bytes (this is the data to store), we write it in memory (which is the array of bytes from mmap), and return the index where we wrote it. - Read(pos) -> []byte
We return the data stored at position - Free(pos)
We remove the data present in the position(index)
Note: The position returned from write acts like an object’s reference address.
Let us go through a scenario to understand how these functions should work. We assume an MMAP-ed byte array of size 15 is with us.

The last step (6) is an interesting one. C was written where A was previously freed. To achieve this,
- The Write operation should know about the free slots currently available so we need GetFreeSlot(size) where size = size(data)
- The Free operation should be able to AddFreeSlot(start, end) where start & end are indices of the free slot.
If we were to devise the above two functions as a competitive programming problem, It’d go something like this…
Problem 1 (easy):
Given a stream of non-overlapping intervals, find an interval that satisfies the given size.
Example:
Input: [ [20,23], [10,20], [30,50], [0,7], [55,59] ], size: 10
Output: [10,20] (or) [30,50]
The actual scenario is much more complicated than the question, as in our real project the free slots will get used up. Let us say we have a binary search tree (assume to be self-balancing) with the interval size as key. That makes both the functions execute in O(lg N).
We can anticipate the free slots becoming more & more fragmented over time. Even in the above example, if the size is 40, we do have space for that but it is fragmented. Let’s work on that.
1. Merging Adjacent free slots

If we get a Free Slot that is adjacent to an existing Free Slot, then we could merge them together to form a larger free slot.
Problem 2 (medium-hard):
This extension to Problem 1 asks for AddFreeSlot(start, end) to merge neighbors which require our BST to be sorted by the free slot’s start index. But if we do that we’d lose our efficiency in GetFreeSlot(size)
I built a Treap for this with the start of free slot interval as BST key and size of the free slot to be used as max heap.
Treap data-structure simultaneously maintains the property of a tree and heap. An awesome visual explanation can be found here.
The nodes are arranged based on the free slot interval’s start while also maintaining max heap property on size (root node is always the largest interval free slot)
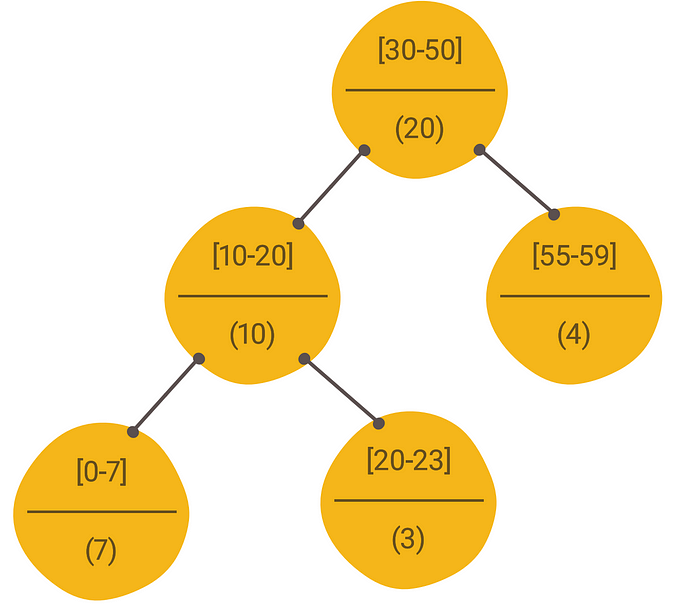
The tree on the left is the treap representation for the input from Problem 1.
The top part of the node indicates the free slot interval and the bottom indicates the size of the free slot.
Since we are not asked to provide a best-fit during GetFreeSlot(size), extracting the root will always return the largest known FreeSlot (root).
2. Combining non-adjacent free slots
When we have fragmented memory, we’ve to move the data around to make space for the new data. Instead of thinking in terms of “data moves to the left”, let us think in terms of “free slots moving to their right”.
At this point, it’d be worth to learn about external and internal fragmentation.

To make this happen, we start by picking up a free slot (not the last one) and shift it to the right (move data to left), until we merge with the neighboring free slot. We continue until the expected size is satisfied. Essentially, we are going to solve the problem of external fragmentation by lazy compaction of data i.e, we compact the data on demand to get the required free space.
Recall that Read(pos) call in our interface. If we move the data, then wouldn’t that change the position? Absolutely. So the trick is to maintain a map of virtual position and update the positions internally.
If there are multiple ways to choose free slots to satisfy the size requirements, how can we go about choosing them? Remember, our goal is to actually reduce the amount of data movement.
So one could come up with an algorithm to determine a plan that’d result in the minimum cost but I’ve not done that. I convinced myself by saying that it’d not be optimal to implement that, as the algorithm might require locking the entire memory for calculation (I’d be happy if I am proven wrong!).
Gravity
The mathematical formula for Gravitational force is given by
g = (G*m₁*m₂)/ r²
where m₁ & m₂ are masses of bodies and r is the distance between them.
In short, gravity increases if two bodies are closer and/or if two bodies are larger. Let’s replace the masses of bodies with the size of free slots and let r be the distance between them. Then the gravity of free slot — fs[i] is given by:
g(fs[i]) = size(fs[i]) * size(fs[i+1]) / distance²(fs[i],fs[i+1])
where fs[i+1] is the next closest free slot

When we are trying to find a free slot for merge, we choose the one with the highest gravity and then start merging adjacent free slots till the entire size is satisfied. Then the procedure from Fig 4 takes place. The gravity score here is only used to find the starting node when fragmented free slots need to be merged.
So if free spaces have gravity, is this what dark energy is? 😮
Problem 3 (hard):
This extension to Problem 2 requires finding the next free slot i.e, for any given free slot, we should also be able to retrieve the closest free slot on the right. Let us name this function NextFreeSlot(freeSlot)
Given we already have a treap sorted by the start of the interval, the next free slot is going to be the inorder successor of the node.
Though one can find the inorder successor on demand while doing the merging, I created next and prev pointers to each node, thus forming a doubly linked list within the treap. (A parent pointer was required to ease this process)

The above figure represents the modified treap from Problem 2 that has O(1) access to next and prev pointers. These pointers are filled during insertion and are modified during the removal operations but will remain untouched during the heapification process.
Note for developers
The project could have a multitude of errors and some of the concepts above have no theoretical proof. They were coded on-demand basis.
Any contributions to the project for fixing the bugs or making improvements are more than welcome.
Summary
- Used MMAP region to provide memory for our allocator
- Defined basic Read, Write & Free operation on our allocator
- Merge adjacent free slots and optimized implementation with treap
- Combine fragmented free slots by choosing slots with the greatest gravity

