A Code Take-Away Service
A simple method to maintain and evolve code with schema contracts.
Before we start, for those super-humans who can convert code to blog/documentation here’s the link to the Github Repo.
@skimmable ( The Problem )
- If you’ve ever consumed from an API or a Pub/Sub service then you’d have spent your time digging through the documentation of the writer’s schema (data model).
- If you think reading the documentation is time consuming then have you ever tried updating an API version to get one feature and ended up changing many models?
Even though Open API specifications help save time, we still have to create objects in our preferred language adhering to the schema specifications.
Some services like Confluent’s Schema Registry solves the above problems by storing the schema in the cloud and deserializing it while consuming using the libraries.
This is achieved because some data serialization mechanisms like Protobuf, Avro, Apache Thrift etc., provide code generation based on schema for many languages.
But what if we want to create our own simple schema registry?
@skimmable ( The Thought process )
Let’s zoom out and take a look at the big picture.
Disclaimer: From here on, the analogies might peak in, non-deterministically
# In a documentation only world, we were only given ingredients [schema] and we made the food [code] ourselves.
# Some serialization mechanisms gave us a machines [code-generators] to convert ingredients [schema] to food [code]
# Now, we will try to provide a take-away service and also provide a way to choose between our options
In non-analogical words, we’ve to
- Generate the code from schema using code-generators and somehow make it accessible to the developers for take-away.
- Maintain different versions of the generated code in sync with schema change and let the consumers choose their required version.
Whenever we hear the words “version” and “code”, Git peeks out of our brain stack. So if the developers of the schema, store the schemas in GIT, that takes care of our versioning problem.
Oh.. Wait.. That takes care of almost everything. Not only did we solve versioning, but we also found a place that is accessible to any developer who wants to consume the API.
So, we’ve now got a place to store the ingredients [schema], we also have the machine [code-generators] but we need someone to get the ingredients [schema], put them in the machine [code-generators] and place them in an appropriate shelf [inside git] for pick-up
@Introducing (The SchemaCodeMan)
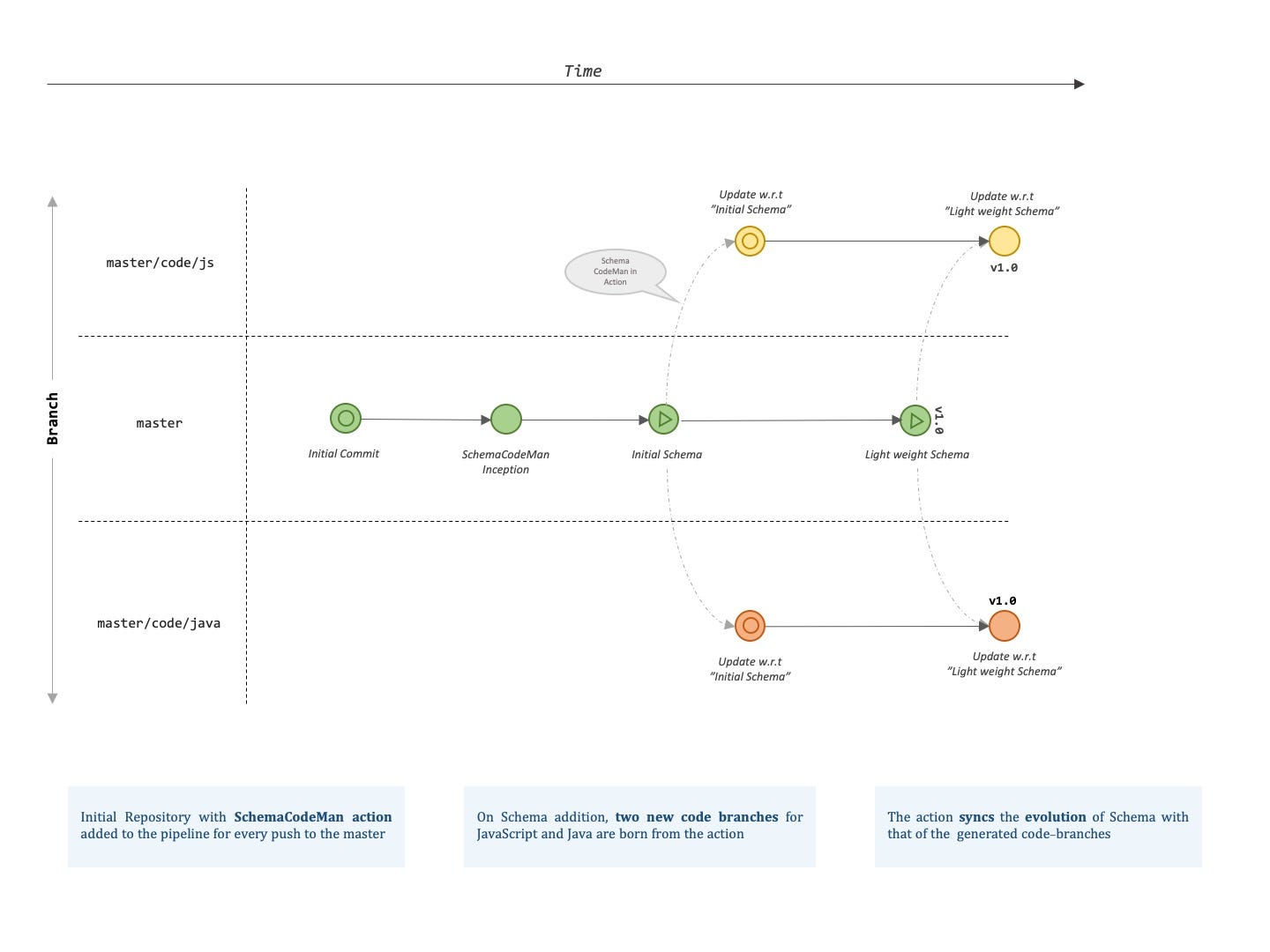
Expanded as Schema Code Manager (currently a prototype) is a Github Action that generates code for the defined schema. The GIF below helps to visualize the connection I’ve tried to establish between the schema, the generated code, and Git.

Click here for unanimated image
@important (The Flow)
- The developers of the schema update their schema in a particular branch and let the schemacodeman know about it.
- The schemacodeman (being a GitHub action) generates the code for the updated schema for each language in a separate branch
- On schema evolution, the code is evolved independently in the respective language branches.
@schema-consumers ( How do we consume the code ? )
- The consumers of the service can clone the language-specific code-branch as a submodule into their repository. One of the main advantages of having language-specific branches
- Upgrading/Downgrading the version is equivalent to checking out the submodule to a specified commit/tag.
@schema-creators ( How do we Setup this flow? )
Add something like the below in your Github Action. Done!
uses: naveenanto22/schemacodeman@v1
with:
languages: 'js,csharp,python'
schema_files: '*.proto,contract/*.proto'For more options & descriptions: naveenanto22/schemacodeman
@skippable ( What happens inside? )
- Schemacodeman generates code based on either custom or default code-generator for each language.
- An orphan code-branch is generated per language and only contains the generated code.
- Each tag in the schema-branch is reflected in the code-branch to specify versions and pre-releases at the code level.
@TheEnd (I hope there’s no coincidental plagiarism)
Oh, you are still reading? I’m glad! Here’s the link to Github Repo again!

{kind=link}